Eureka Rewards and Policies
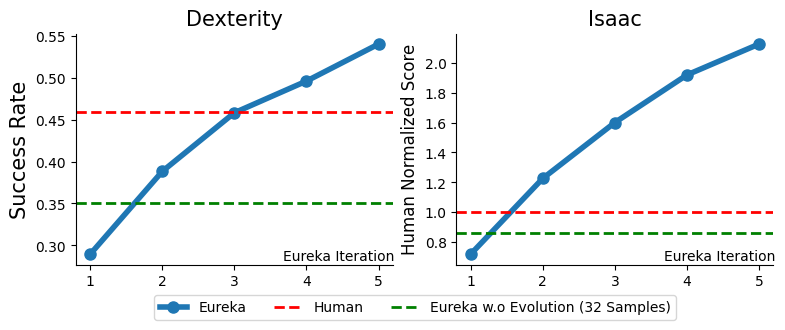
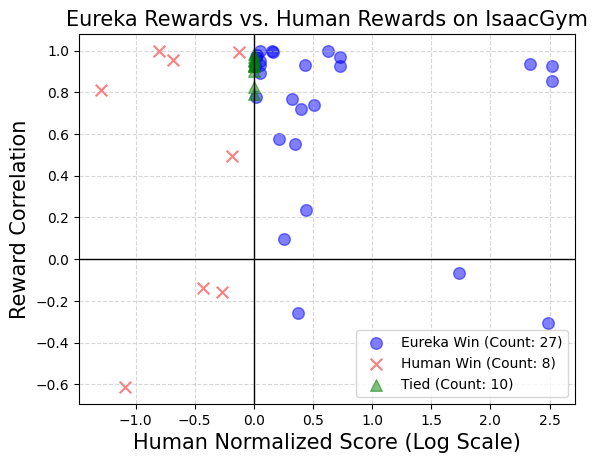
In this demo, we visualize the unmodified best Eureka reward for each environment and the policy trained using this reward. Our environment suite spans 10 robots and 29 distinct tasks across two open-sourced benchmarks, Isaac Gym (Isaac) and Bidexterous Manipulation (Dexterity).
Isaac
![<b>AllegroHand</b>, best Eureka reward:
[sep]
assets/reward_functions/allegro_hand.txt](videos/task_final/allegro_hand.png)
![<b>Ant</b>, best Eureka reward:
[sep]
assets/reward_functions/ant.txt](videos/task_final/ant.png)
![<b>Anymal</b>, best Eureka reward:
[sep]
assets/reward_functions/anymal.txt](videos/task_final/anymal.png)
![<b>BallBalance</b>, best Eureka reward:
[sep]
assets/reward_functions/ball_balance.txt](videos/task_final/ball_balance.png)
![<b>Cartpole</b>, best Eureka reward:
[sep]
assets/reward_functions/cartpole.txt](videos/task_final/cartpole.png)
![<b>FrankaCabinet</b>, best Eureka reward:
[sep]
assets/reward_functions/franka_cabinet.txt](videos/task_final/franka_cabinet.png)
![<b>Humanoid</b>, best Eureka reward:
[sep]
assets/reward_functions/humanoid.txt](videos/task_final/humanoid.png)
![<b>Quadcopter</b>, best Eureka reward:
[sep]
assets/reward_functions/quadcopter.txt](videos/task_final/quadcopter.png)
![<b>ShadowHand</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand.txt](videos/task_final/shadow_hand.png)
Dexterity
![<b>ShadowHandBlockStack</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_block_stack.txt](videos/task_final/bidex_block_stacking.png)
![<b>ShadowHandBottleCap</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_bottle_cap.txt](videos/task_final/bidex_bottle_cap.png)
![<b>ShadowHandCatchAbreast</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_catch_abreast.txt](videos/task_final/bidex_catch_abreast.png)
![<b>ShadowHandCatchOver2Underarm</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_catch_over_2_underarm.txt](videos/task_final/bidex_catch_over2underarm.png)
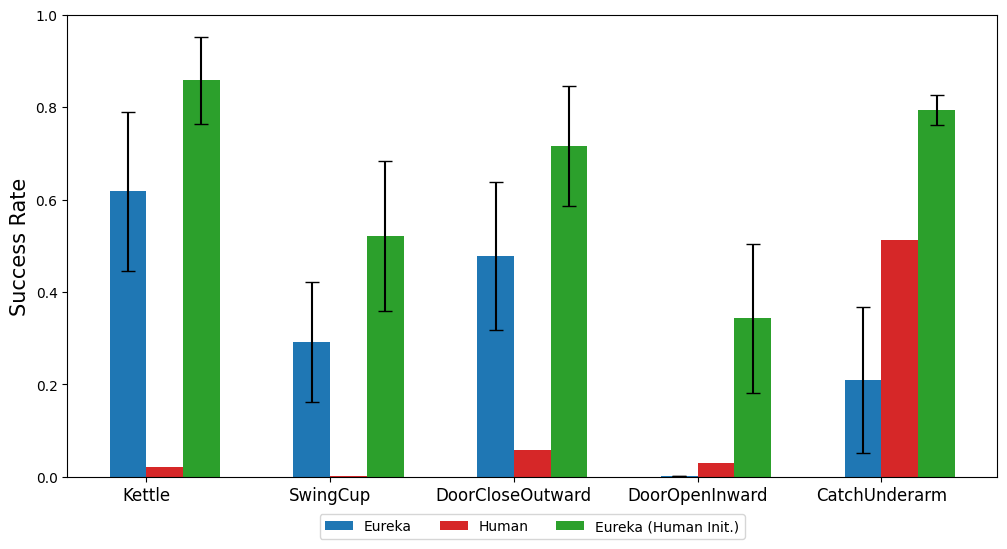
![<b>ShadowHandCatchUnderarm</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_catch_underarm.txt](videos/task_final/bidex_catch_underarm.png)
![<b>ShadowHandDoorCloseInward</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_door_close_inward.txt](videos/task_final/bidex_door_close_inward.png)
![<b>ShadowHandDoorCloseOutward</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_door_close_outward.txt](videos/task_final/bidex_door_close_outward.png)
![<b>ShadowHandDoorOpenInward</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_door_open_inward.txt](videos/task_final/bidex_door_open_inward.png)
![<b>ShadowHandDoorOpenOutward</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_door_open_outward.txt](videos/task_final/bidex_door_open_outward.png)
![<b>ShadowHandGraspAndPlace</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_grasp_and_place.txt](videos/task_final/bidex_grasp_and_place.png)
![<b>ShadowHandKettle</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_kettle.txt](videos/task_final/bidex_kettle.png)
![<b>ShadowHandLiftUnderarm</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_lift_underarm.txt](videos/task_final/bidex_lift_undearm.png)
![<b>ShadowHandOver</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_over.txt](videos/task_final/bidex_over.png)
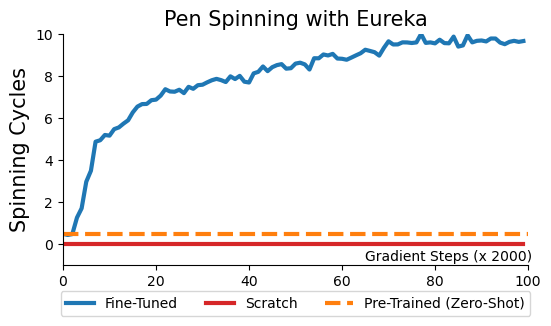
![<b>ShadowHandPen</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_pen.txt](videos/task_final/bidex_pen.png)
![<b>ShadowHandPushBlock</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_push_block.txt](videos/task_final/bidex_push_block.png)
![<b>ShadowHandReorientation</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_reorientation.txt](videos/task_final/bidex_re_orientation.png)
![<b>ShadowHandScissors</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_scissors.txt](videos/task_final/bidex_scissors.png)
![<b>ShadowHandSwingCup</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_swing_cup.txt](videos/task_final/bidex_swing_cup.png)
![<b>ShadowHandSwitch</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_switch.txt](videos/task_final/bidex_switch.png)
![<b>ShadowHandTwoCatchUnderarm</b>, best Eureka reward:
[sep]
assets/reward_functions/shadow_hand_two_catch_underarm.txt](videos/task_final/bidex_two_catch_underarm.png)
Select an image above:
Eureka response shown within code block.

![<b>Iteration 1</b>, best Eureka reward:
[sep]
assets/rlhf_rewards/humanoid_step0.txt](videos/humanoid_rlhf/humanoid-step0.png)
![<b>Iteration 2</b>, Human feedback: <br>
<span style="font-size: 0.8em; line-height: 30px;">The learned behavior resembles forward squat jump;
please revise the reward function so that the behavior resembles forward running.</span><br><br>
<b>Iteration 2</b>, Eureka reward:
[sep]
assets/rlhf_rewards/humanoid_step1.txt](videos/humanoid_rlhf/humanoid-step1.png)
![<b>Iteration 3</b>, Human feedback: <br>
<span style="font-size: 0.8em; line-height: 30px;">The learned behavior now looks like duck walk;
the legs are indeed alternating but the torso is very low.
Could you improve the reward function for upright running?</span><br><br>
<b>Iteration 3</b>, Eureka reward:
[sep]
assets/rlhf_rewards/humanoid_step2.txt](videos/humanoid_rlhf/humanoid-step2.png)
![<b>Iteration 4</b>, Human feedback: <br>
<span style="font-size: 0.8em; line-height: 30px;">The learned behavior has the robot hopping on one of its foot in order to move forward.
Please revise the reward function to encourage upright running behavior.</span><br><br>
<b>Iteration 4</b>, Eureka reward:
[sep]
assets/rlhf_rewards/humanoid_step3.txt](videos/humanoid_rlhf/humanoid-step3.png)
![<b>Iteration 5</b>, Human feedback: <br>
<span style="font-size: 0.8em; line-height: 30px;">This reward function removed the penalty for low torse position that you added last time; could you just add it back in? </span><br><br>
<b>Iteration 5</b>, Eureka reward:
[sep]
assets/rlhf_rewards/humanoid_step4.txt](videos/humanoid_rlhf/humanoid-step4.png)
![<b>Eureka without RLHF</b>, best Eureka reward:
[sep]
assets/reward_functions/humanoid.txt](videos/humanoid_rlhf/humanoid-norlhf.png)